The following is intended to be a primer on deployment architecture for systems engineers & software engineers. This is the first architecturally focused post on this blog. The hope is that it will serve as a foundation for future architecturally focused blog posts that I hope you find value in.
The Motivation For This Article
I have been an Operations Architect by trade for many years. One of the primary functions I have in this role is reviewing each teams software architecture to figure out the right way to deploy & scale their system while providing the maximum availability for it, and while not jeopardizing the existing more complex system. One of the most important lessons I learned about software architecture while doing this role many years ago, was the difference between a stateless and stateful service. Why you ask ? In short because knowing whether a service was stateless or stateful dictated how I should scale & provide high availability to the service on the infrastructure side. It told me the proper deployment architecture to use.
What Are Stateless Services ?
A stateless service is a service that can handle each incoming request, without knowing anything about any previous request. Meaning, the processing of any request doesn’t require getting data about any previous requests from a database or session store. What this means is that each instance of this service (in our example a web server) can be scaled independently. To provide maximum availability for a stateless service all you need are instances ! Lot’s and lot’s of instances/nodes/vms/containers etc.. aka redundancy ! Very simple right ? And you should have seen this a thousand times if you have ever run an infrastructure that supports a website.
How To Deploy & Scale Stateless Services
Here is a quick picture of how we scale a stateless service.
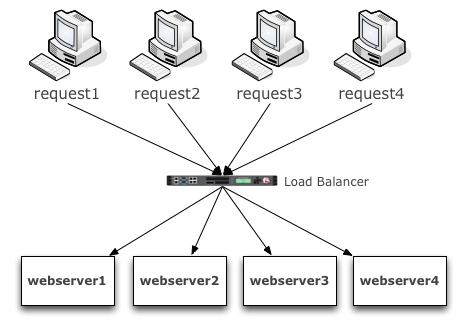
Pretty straight forward. No matter how many incoming requests there are, they can be distributed amongst X number of web servers. The application running on each web server will reply with the correct response, because it has everything it needs to reply. More to the point it doesn’t need to lookup any previous result or ‘state’ information in a database somewhere to know what to reply with. If we need more capacity, we add more web server instances. If one of the web servers fail, we have X number of servers behind the load balancer, that can still handle the requests. You should be able to see clearly how easy it is to scale and provide high availability for stateless services. Most companies deploy this kind of pattern regionally, such that you can lose an entire region and requests will still be processed in another region. Anyone who runs on AWS, like Netflix for example, does this for their stateless services. Now let’s talk about the uglier brother.
What Are Stateful Services?
If stateless services are services that can process requests without knowing anything about the previous request, it should be pretty self explanatory what a stateful service is right 😉 ?
A stateful service is a service that depends on the result of a previous request to process a subsequent request. If a web request depends on the result of a previous request, how would it get that result ? By looking that result up in a database. However, in order to look up the result of a previous request, we have to know something about the request we want to look up. For example, the user or unique session id the request came from. If we knew the user or session that performed the original request, we could then query for that result when the subsequent request comes in from that user. But how is this actually implemented ?
Usually, upon the initial request a session cookie is created, in it a unique identifier is stored and upon subsequent requests from that same browser the web server receiving the request also receives the unique identifier and can query the database for whatever information it needs related to the users session. The information in that session is called ‘state’ and it is usually modified frequently as the user makes more requests moving about the website.
Before we move here is a quick graphic of this architecture
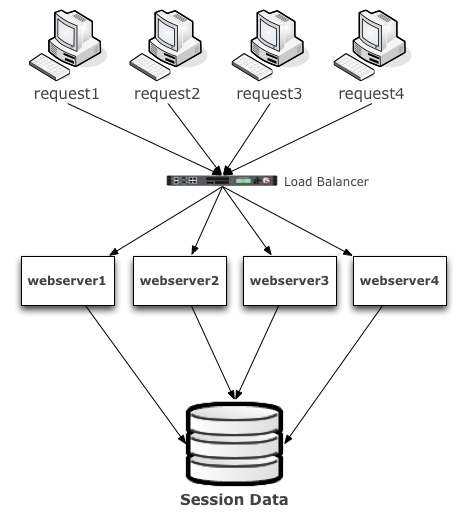
Btw, have you ever heard someone say, my applications requires sticky or persistent load balancing ? That is because their application is stateful, but they do not have a session store. Forcing the load balancer to send the request back to the same machine is a cheap & horrible way to solve this problem. </end rant> Moving on…
How To Deploy & Scale Stateful Services
There are two approaches to deploying stateful services ‘active/active’ and ‘active/passive’. Active/Active is the preferred deployment pattern, but it is also more cumbersome to deploy. To keep this example simple, we will avoid NoSQL flavors in our example (although these are commonly preferred for session stores) and use MySQL in our example instead.
Active/Active MySQL
Active / Active also known as Multi-Master refers to having two or more (database) nodes or instances available AND servicing requests actively using two or more nodes. The benefits of Active/Active are bountiful. You can lose a node, without having to failover. You can add a node to scale out for more capacity & performance. As with anything there are limits to how far out you can scale, but active/active still the best deployment architecture for databases today.
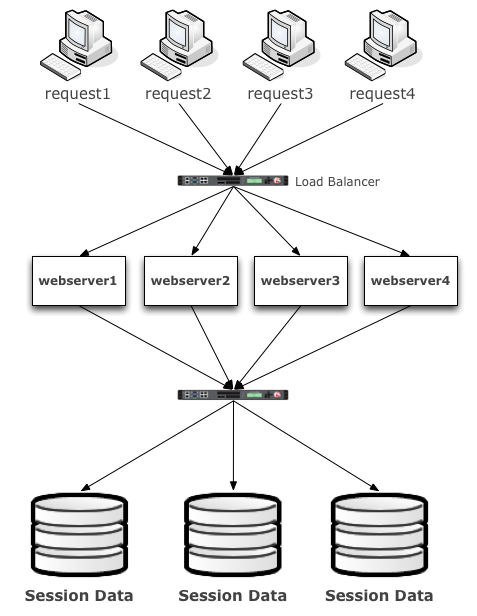
Btw, if you deploy this architecture make sure you pay special attention to your Load Balancer layer. In my opinion a pair of active/passive LTMs is not enough. Remember your availability is only as good as your weakest link. Solves here might include, Any Cast, BGP, GTM, and replication + retry to other regions.
Active/Passive MySQL
Active/Passive aka Master/Slave refers to having one database node or instance available to service requests actively and having another spare node that can be elected as the master (i.e. failed over to) in the event of a failure on the primary node. Again, this is easier to implement, but does not scale as well, nor does it provide great availability due to the time it takes to failover and due to the fact that a failover node is typically not regularly tested. A ‘warm’ node where transactions are constantly being ran through it aka the active/active pattern we discussed in the previous example is always superior.
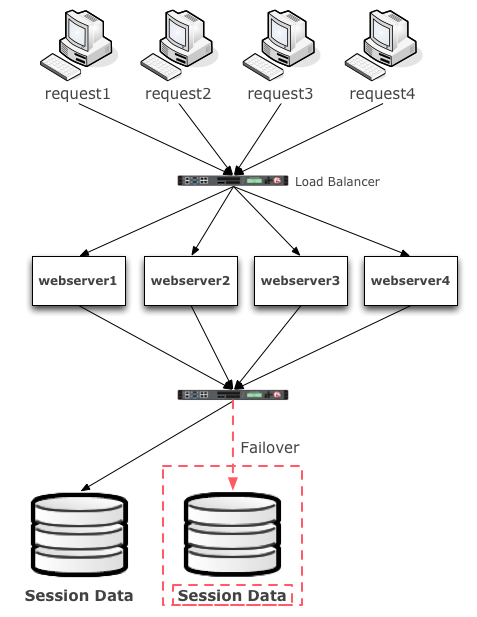
Summary
Early in my career I learned these application characteristics and common patterns for how to deploy applications with these constraints in the best way possible. However, this is the tip of the ice berg. With todays technology stacks we are running a lot more than just websites. Many systems being deployed now include things like Message Buses, NoSQL stores, and Clusters. Each of these categories and more importantly the technologies within them have additional features & constraints surrounding their availability and scalability. My hope is that this article gave you a strong foundation for you to continue your own learning as it relates to deployment architecture & infrastructure for stateless and stateful systems so that you can deploy scalable & highly available architectures.
Keep Learning,
Jason Riedel