How To: Maximize Availability Effeciently Using AWS Availability Zones
For the TL;DR version, skip straight to the Cassandra Examples
Intro & Background
During my years at PayPal I was fortunate enough to be a part of a pioneering architecture & engineering team that designed & delivered a new paradigm for how we deployed & operated applications using a model that included 5 Availability Zones per Region (multiple regions) & Global Traffic Management. This new deployment pattern increased our cost efficiency and capacity while providing high availability to our production application stack. The key to increasing cost efficiency while not losing availability is how you manage your capacity. Failure detection and global traffic management go the rest of the way to make use of all your Availability Zones & Regions giving you better availability. There is a little more to it, in terms of how you deploy your applications advantageously to this design…but we will get into that with our Cassandra/AWS examples later.
Prior to this model our approach was the traditional 3 datacenter model. 2 Active + 1 DR all with 100% of the capacity required to operate independently and they required manual failover in the event of an outage.
Oh the joys of operating your own private cloud & datacenters at scale 🙂
Most companies and a recent article suggests PayPal as well, are thinking about or are moving to public cloud. Public cloud gives most companies cheaper and faster access to the economy of scale as well as an immediate tap into a global infrastructure.
Amazon Web Services (AWS) is the market share leader in public cloud today. They operate tens of Regions & Availability Zones all around the world. Deploying your application(s) on these massive scale public clouds means opportunity for operating them in more efficient ways.
Recently I came across a few articles that felt like reading a history book on going from a Failover to an Always On model. I’ll just leave these here for inquiring minds…
http://highscalability.com/blog/2016/8/23/the-always-on-architecture-moving-beyond-legacy-disaster-rec.html
https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/44686.pdf
Ok enough with the introduction, lets move into the future, starting with the Principles of High Availability.
Principles for High Availability – Always
- Use Multiple Regions ( Min 2, Max as many as you need)
- Use Multiple Availability Zones ( Min 2, Max as many as is prudent to optimize availability and capacity with cost )
- Design for an Active/Active architecture
- Deploy at least N+1 capacity per cluster when Active/Active is not easily accomplished
- Note: N=100% of capacity required to run your workload
- Eliminate Single Points of Failure/Ensure redundancies in all components of the distributed system(s)
- Make services fault tolerate/Ensure they continue in the event of various failures
- Make services resilient by implementing timeout/retry patterns (circuit breaker, exponential back off algorithm etc)
- Make services implement graceful failure such as degrading the quality of a response while still providing a response
- Use an ESB (Enterprise Service Bus) to make calls to your application stack asynchronous where applicable
- Use caching layers to speed up responses
- Use Auto-Scaling for adding dynamic capacity for bursty workloads (This can also save money)
- Design deployments to be easily reproduced & self-healing (i.e. using Spinnaker(Netflix), Kubernetes (Google) for containers, Scalr etc)
- Design deployments with effective monitoring visibility – Synthetic Transactions, Predictive Analytics, event triggers, etc.
Principles for High Availability – Never’s
- Deploy to a single availability zone
- Deploy to a single region
- Depend on either a single availability zone or region to always be UP.
- Depend on capacity in a single availability zone in a region to be AVAILABLE.
- Give up too easily on an Active/Active design/implementation
- Rely on datacenter failover to provide HA (Instead prefer active/active/multi-region/multi-az)
- Make synchronous calls across regions (this negatively effects your failure domain cross region)
- Use sticky load balancing to pin requests to a specific node for a response to succeed (i.e. if you are relying on it for ‘state’ purposes this is really bad)
Summarizing
- YOU MUST deploy your application components to a minimum of 2 Regions.
- Because failures of an entire region in AWS happen frequently…
- YOU MUST deploy your application components to a minimum of 2 Availability Zones within a Region.
- Because an AWS AZ can go down for maintenance, outage or be out of new capacity frequently…
- YOU MUST aim to maximize the use of Availability Zones and Regions, but balance that with cost requirements and be aware of diminishing returns
- YOU MUST use global traffic routing (Route53) and health-check monitoring/ automated markdowns to route around failure to healthy deployments
- YOU MUST follow the rest of the Principles of High Availability Always directives to the best of your ability
Active/Active Request Routing (AWS)
Diagram Components
- Global Traffic Management: Using AWS Route53 as a Global Traffic Manager (configuring Traffic Flows + geolocation)
- 3 Regions = AZ’s: us-east-1 = 4, us-west-2 = 3, eu-central-1 = 2
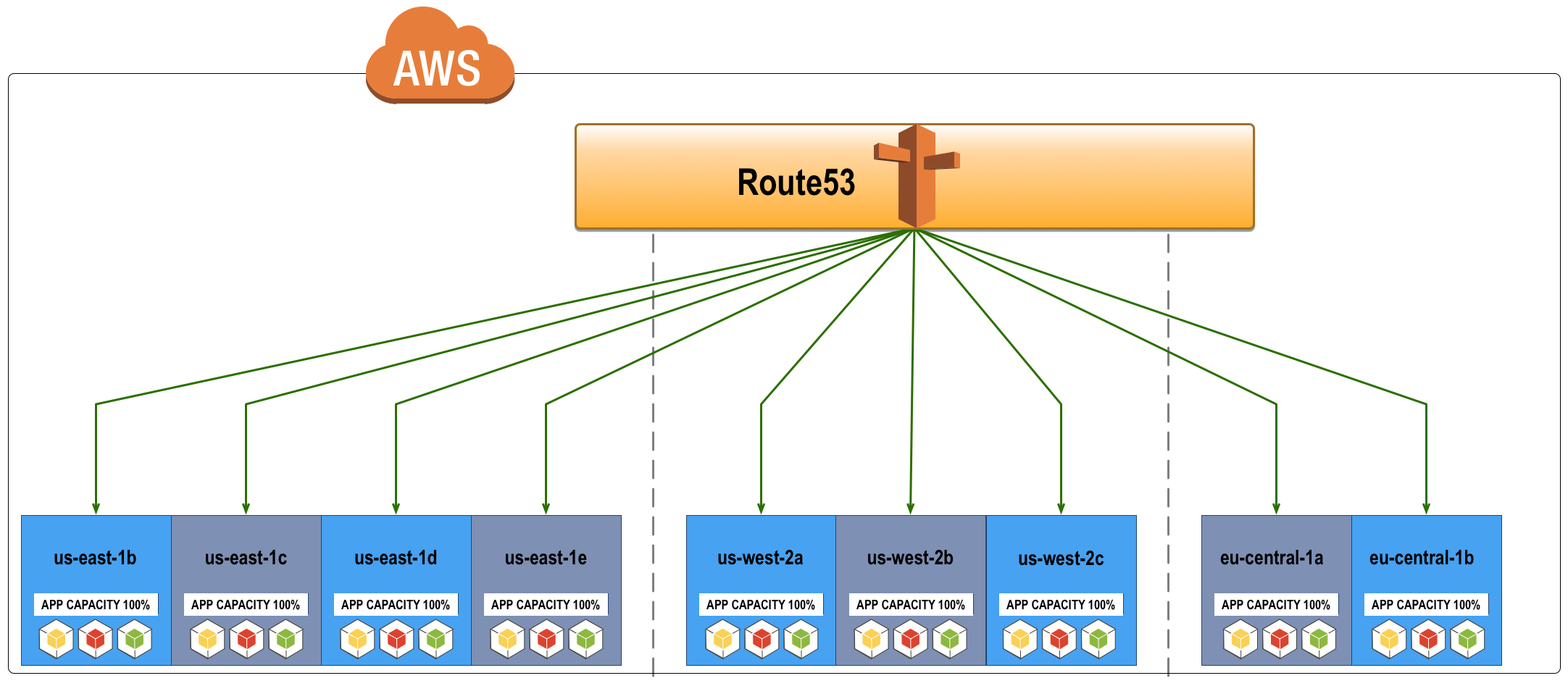
Additional Info on Active/Active Request Routing
- Route53 load balances requests to the application stack within each availability zone and across 3 regions.
- This is an Active/Active design, i.e. Route53 is configured to route requests to all available zones until one fails. (Traffic Flow + Geolocation)
The Design Above Is Actually Wasteful (Cost & Capacity must be optimized for HA)
- This example shows all application deployments (& components) in every AZ deployed with 100% capacity required to run without another AZ
- This means you could lose ALL, BUT ONE availability zone and still service requests from your one remaining AZ
While this would achieve the highest availability, it is not the most optimal approach because it is wasteful
- Each application team must decide the right mix of regions, availability zones & capacity to provide HA at the lowest cost for their consumers based on their application requirements
- Depending on how much capacity you deploy for your application per AZ it is possible to deploy too much/many and have diminishing returns on availability while wasting a lot of $$$
- You must find the right balance for your application & business contexts ( see below examples with Cassandra for more details on how this approach can be wasteful )
Understanding Availability Zones
The crux of achieving a highly available architecture lies within the proper usage & understanding of Availability Zones. If you ignore everything else, read this section !
What Do AZ’z Provide ?
- Availability Zones consist of one or more discrete data centers
- Each with redundant power
- Networking and connectivity
- Housed in separate facilities
- Source : https://aws.amazon.com/about-aws/global-infrastructure/
In Amazon’s own words:
“Each region contains multiple distinct locations called Availability Zones, or AZs. Each Availability Zone is engineered to be isolated from failures in other Availability Zones, and to provide inexpensive, low-latency network connectivity to other zones in the same region. By launching instances in separate Availability Zones, you can protect your applications from the failure of a single location.” Source: http://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.RegionsAndAvailabilityZones.html
How to think of an AZ
- In the AWS World it is helpful to use the analogy of an Availability Zone being a Rack in a traditional datacenter
- I.E. instead of striping a Cassandra cluster across Racks, you would do it across Availability Zones.
What about using an Availability Zone as a complete application failure domain ?
- In a traditional private datacenter an Availability Zone is a separate datacenter container, with shared network (although it can be isolated as well).
- It is built/populated with the required infrastructure & capacity to run the applications and it has all the physical characteristics mentioned above that the AWS AZ has
- However, the way it is used in a private datacenter can be different, because YOU have full visibility & control of capacity
- For example, you could limit service calls such that service calls are to/from the same AZ, effectively creating a distinct application failure domain, piggy-backing the already distinct infrastructure failure domain (provided by an Availability Zone)
Why not use an AWS Availability Zone as a distinct application failure domain then ?
- You can, but this fails to be robust in the public cloud context because capacity might not always be available in the AZ and you don’t know when it will run out
- BEING CLEAR – You can run out of capacity in an Availability Zone FOREVER. The AZ will still be available to manage existing infrastructure/capacity, but new capacity cannot be added
- This would negatively effect auto-scaling & new provisioning and ultimately implies you cannot rely on a single AZ to be treated as a datacenter container
- To continue operating when an AZ runs out of capacity in public cloud you have to utilize a new AZ for new capacity
- That new AZ would follow the same isolated service calls principles except now 2 AZ’s would be called as part of a failure domain
- Effectively multiple AZ’s would become a single failure domain organically
- Therefore, it is not advantageous in the public cloud world to try to treat a single AZ as a failure domain
- Instead stripe applications across as many AZ’s as necessary to provide up to N+2 capacity per Region while minimizing waste.
- The region becomes the failure domain of your application and this is a more efficient use of AZs to provide availability in the public cloud context
- This is why N+N regions is paramount in managing your availability in public cloud
What is the latency between Availability Zones ?
- Tests with micro instances (they have worst network profile) show that the latency between AZ’s within a region is on average 1ms
- Most workloads will have no challenge dealing with 1ms latency and taking full advantage of availability zones to augment their availability
- However, some applications are very chatty, making hundreds to thousands of calls in series
- These workloads often must be re-architected to work well in a public cloud environment
What happens if I do not use multiple Availability Zones ?
Truths…
- An Availability Zone can become unavailable at any time, for any reason
- An Availability Zone can become unavailable due to planned maintenance or an outage
- An Availability Zone can run out of capacity for long periods of time and indefinitely (forever)
Thus the result of not deploying to multiple availability zones is…
- Provisioning outages for new capacity and the inability to self-heal deployments
The reality is…
- If you only deploy to a single AZ in a Region, you guarantee that you will experience a 100% failure in that Region, when the AZ you rely on becomes unavailable
- You can failover or continue (if Active/Active) to service transactions in another Region, but you can achieve higher availability per Region by striping your application deployment across multiple AZ’s in a region
- And you have less latency to deal with when failing over to another AZ locally vs. an AZ in a remote region
Finding The Right Balance Between High Availability & Cost
Often times availability decisions come with a cost. This section will describe a more practical and better way to achieve high availability infrastructure for your application while keeping the costs within reason. It is important to note, cost optimization heavily depends on application context, because you must first figure out the lowest common denominator of AZ’s / Regions you can use and still achieve your target availability. This typically depends on the number of required AZ’s to achieve quorum for stateful services. For example, if we were configuring Cassandra for eventual consistency + high availability, we would want 5 nodes in the cluster and a replication factor of 3. We would want to the best of our ability to spread those nodes across AZ’s.
100% of application capacity deployed to every Availability Zone is bad
- The traffic routing example in the beginning shows 100% capacity being deployed for every application component in every AZ
- As covered previously and shown in the later sections, this is a sub-optimal deployment strategy.
- Instead you must stripe your applications capacity across AZ’s, keeping in mind a target of at least N+1 capacity or N+2 where possible
What if I deploy 100% of application capacity to only two of Availability Zones per Region?
- Let’s assume we are talking about MySQL or another RDBMs with ACID properties.
- You might want to deploy MySQL as a master/master where each master is in a separate AZ and can support 100% of the required capacity
- Given this configuration you have met the N+1 requirement per Region
- This might be acceptable to you from the availability perspective, however keep in mind you do not control when those AZ’s become unavailable or worse run out of new capacity.
- Always make sure an application like this is able to be redeployed through automation (i.e. self-healing) in another availability zone
Stateless/Stateful Applications & Capacity Defines the number of AZ’z per Region you need
- Stateless applications are much easier to provide high availability for. You simply maximize redundant instances across AZ’s within reason (cost being the reason/limiting factor)
- So effectively with stateless applications you tend to deploy to as many AZ’s as you have available
- But what should determine the number of AZ’s you utilize per region is your stateful applications requirements for quorum or availability and how you choose to manage capacity
Examples of balancing High Availability & Cost using Apache Cassandra in AWS
This Cassandra calculator is a useful reference for this section
http://www.ecyrd.com/cassandracalculator/
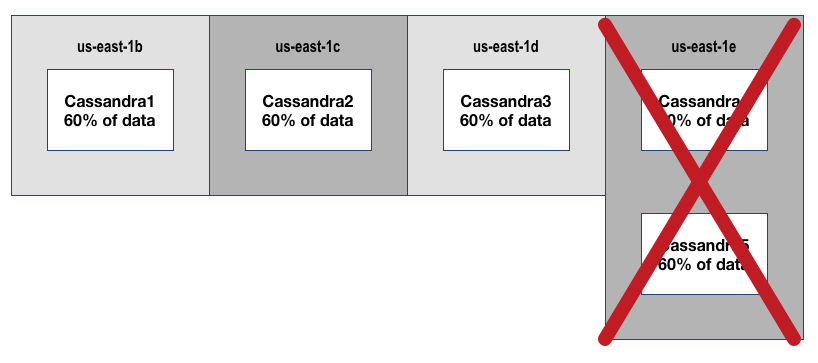
Cassandra N+1 ( 4 AZ’s ) – Wasteful Version
The following assumes Cassandra is configured for eventual consistency with the following parameters:
- Cluster Size=5, Replication Factor=3, Write/Read=1
- Region=us-east-1, Available AZ’s=4
Diagram Explanation
- In this configuration you can lose 2 nodes without data availability impact
- If you lose a 3rd node you would lose access to 60% of your data
- Your node availability is N+2. HOWEVER, because you have only 4 AZ’s in us-east-1 that can be used, 2 nodes are required to be in 1 AZ
- The available AZ’s in the region reduces your overall availability as a whole to N+1 in the event of ‘us-east-1e’ becoming unavailable
- Thus the 5th node is completely unnecessary and wasteful !
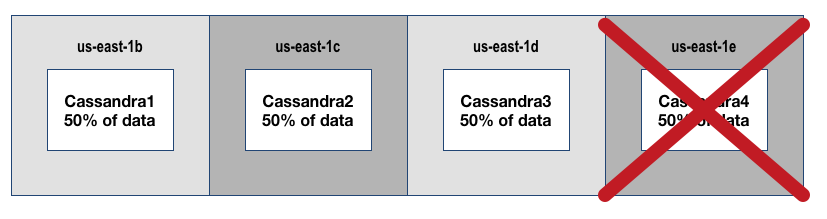
Cassandra N+1 Cost Optimized (4 AZ’s) Version
The following assumes Cassandra is configured for eventual consistency with the following parameters:
- Set Cluster Size=4, Replication Factor=2
- Region=us-east-1, Available AZ’s=4
Diagram Explanation
- You can now lose 1 node or one availability zone and still service 100% of requests
- Losing a 2nd node result in 50% impact to data accessibility
Cassandra N+2 Cost Optimized (4 AZ’s) Version
- Set Cluster Size=4, Replication Factor=3
- Region=us-east-1, Available AZ’s=4
Diagram Explanation
- In order to optimize for cost and achieve N+2 you must have at least 4 AZs available
- Otherwise, 100% of data per node is required to achieve N+2 with only 3 AZ’s
- A better scenario is having 4 AZ’s or more where you can play with Replication Factor (aka data availability thus capacity needed to run the service)
- To achieve cost optimized N+2 with 4 AZ’s we will set cluster size to 4 and Replication Factor to 3 resulting in this diagram/outcome
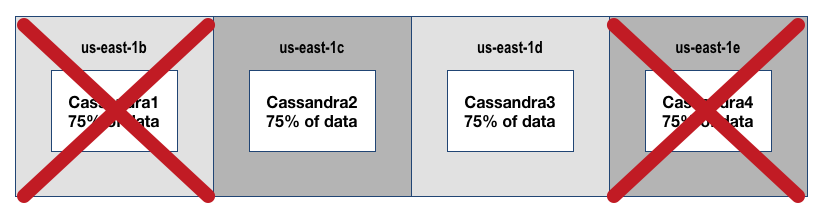
This achieves the following
- You can lose any 2 nodes or AZ’s above, and continue to run. If you lose a 3rd node you would have 75% impact to your data availability and need to fail/markdown the region for another region to takeover.
- Also if you have a 4 node cluster with a replication factor=4 you have 100% of data on each node…this is not cost optimized for availability, but allows you to lose 3/4 nodes.
- However, N+3 is considered too many eggs in one region and thus is not the right approach.
- Instead if you architect for N+2 in each region + have global traffic management routing to active/active deployments, you will maximize your availability.
Cassandra With Only 2 Availability Zones
- us-east-1 has 4 AZ’s this is actually a high number of available regions for AWS, in regions like us-west-2 and us-central-1 you only have 3, and 2 AZ’s respectively.
- To clearly show the risk of ignoring availability zones & capacity while architecting for availability let’s look at the extreme case of deploying in eu-central-1 changing nothing else
- Again we use a Cluster Size=5,Replication Factor=3 as our initial example
- eu-central-1 has only 2 AZ’s
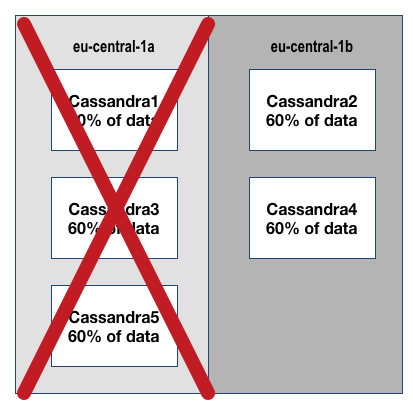
- As you can see if you lose eu-central-1a you lose 3 nodes at one time and 60% of your data becomes inaccessible.
- If you lose eu-central-1b you are ok because you have > 100% of the required data available provided by your remaining nodes, but you cannot lose another node.
- You cannot and should not ever deploy a service this way. Instead you need to tune the Cassandra cluster for the number of AZ’s.
- Setting Cluster Size=2 and Replication Factor=2 for eu-central-1 allows an N+1 design
- Unfortunately, cost optimization is not possible with only 2 AZ’s
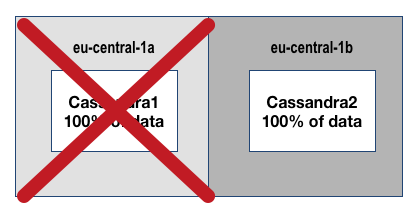
- You can lose either node or AZ, and still have access to 100% of your data. You must lose access to the region or both AZs/nodes to have a service impact
- You cannot achieve true N+2 with only 2 AZ’s in a region (You can achieve it via node redundancy only)
- What I recommend in this case is have multi-region deployments (kudos if they happen to be in different public clouds), but within AWS deploy to eu-central-1 + eu-west-1 using N+1 deployments & global traffic management to achieve higher availability than a single region deployment would allow.
I hope this lengthy overview helps someone somewhere struggling with how to deploy applications to Availability Zones in AWS.
Feel free to contact me with any questions or corrections, thanks for reading !
How To: Maximize Availability Effeciently Using AWS Availability Zones Read More »