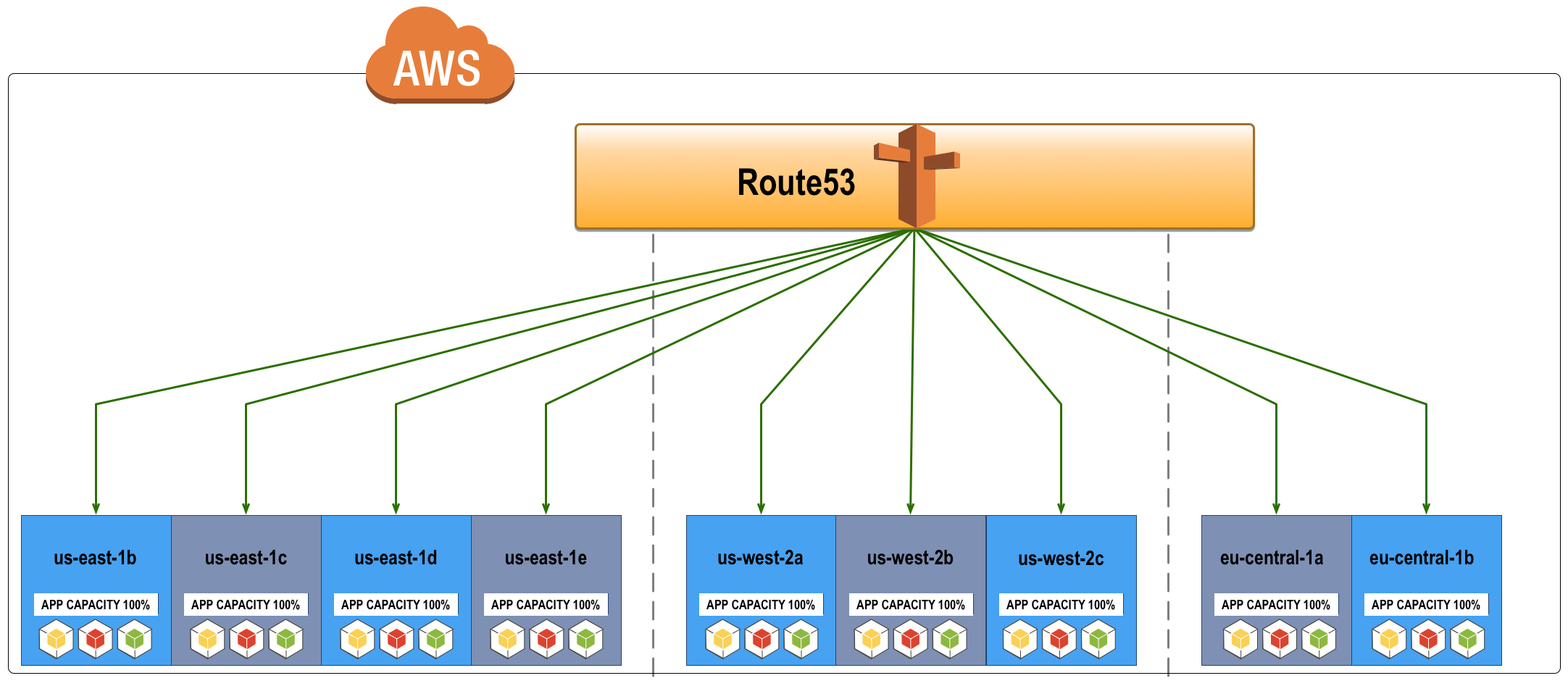
If you are running any kind of environment with greater than 10 servers, than you need a CMDB (Configuration Management DataBase). CMDB’s are the brain of your fleet & it’s environment. You can store anything in a CMDB, but commonly the metadata in CMDB’s consists of any of the following physical & digital asset inventory, software licenses, software configuration data, policy information, relationships (I.E. This VM—> Compute –> Rack –> Availability Zone –> Datacenter), automation metadata, and more… they also commonly provide change history for changes in your environment.
In the world of infrastructure as code, CMDB is king.
CMDB’s enable endless automation possibilities, without them you are stuck gathering and collecting ‘current’ configuration state about your infrastructure every time you want perform an automated change or run an audit/report . In my career I have built or been a part of CMDB efforts at nearly every company I have worked for. They are simply necessary, and by their nature they tend to require the choice of ‘built by us’ vs ‘buy or run’.
However, if you have the luxury of only running in AWS, you are in luck, because Netflix (The AWS poster child) open sourced Edda in 2012 for this purpose!
Rather than talk about the specific features of Edda refer to the blog post or documentation, I want to keep this article short and jump right into setting up Edda, which is a bit tricky, because the documentation is out of date!
Setting Up Edda (2016)
First, in AWS you need setup an EC2 VM that has at least.. 6G for OS + dependencies including Mongo, and then however much disk you need to store the metadata for your environment (keep in mind it keeps change history). Personally I just created a root partition with 100G to keep things simple. For instance type I used ‘m4.xlarge’ and the Ubuntu version is 14.04.
After booting the VM, SSH to it and create a directory wherever your storage is allocated partition wise to store Edda & it’s dependencies. I will be using /cmdb/ in my example.
Initial Install Steps
mkdir /cmdb cd /cmdb export JAVA_OPTS="-Xmx1g -XX:MaxPermSize=256M" git clone https://github.com/Netflix/edda.git sudo add-apt-repository -y ppa:webupd8team/java &> /dev/null sudo apt-get update sudo debconf-set-selections <<< 'oracle-java8-installer shared/accepted-oracle-license-v1-1 boolean true' sudo apt-get install -y oracle-java8-installer sudo apt-get install -y scala sudo apt-get install make cd /cmdb/edda make build
For the record, the Edda Wiki has the build steps wrong, it appears they no long are using Gradle, but have switch to SBT… which reminds me be aware Edda is written in Scala, which isn’t as popular as Java, Python etc… in addition it’s functional programming, which I don’t personally know a lot about, but I hear it’s got quite the learning curve..so beware if you need to make custom code changes, I would not recommend it, unless you know Scala ! 🙂
After the build of Edda succeeds, install Mongo
apt-get install -y mongodb
That’s it for dependencies
Configuring Mongo
For Edda to use Mongo all we need to do is ‘use’ the database we want to use for Edda & create an associated user. (Mongo will auto-create DB’s upon insert).
mongo
> use edda
> db.addUser({user:'edda',pwd:'t00t0ri4l',Roles: { edda: ['readWrite']}, roles: []})
You can test the user is working by doing…
$ mongo edda -u edda -p MongoDB shell version: 2.4.9 Enter password: connecting to: edda Server has startup warnings: Sat Dec 10 00:53:21.093 [initandlisten] Sat Dec 10 00:53:21.094 [initandlisten] ** WARNING: You are running on a NUMA machine. Sat Dec 10 00:53:21.094 [initandlisten] ** We suggest launching mongod like this to avoid performance problems: Sat Dec 10 00:53:21.094 [initandlisten] ** numactl --interleave=all mongod [other options] Sat Dec 10 00:53:21.094 [initandlisten] >
Configuring Edda
Under /cmdb/edda/src/main/resources we need to modify ‘edda.properties’ with valid config values for accounts, regions & mongo access.
Relevant Mongo Values
edda.mongo.address=127.0.0.1:27017 edda.mongo.database=edda edda.mongo.user=edda edda.mongo.password=t00t0ri4l
Account & Region Values
edda.accounts=dev.us-east-1 edda.dev.us-east-1.region=us-east-1 edda.dev.us-east-1.aws.accessKey=fakeaccesskey edda.dev.us-east-1.aws.secretKey=fakesecret
The above example is using one account and only one region. The Edda configuration uses generic labels, they are very flexible, but when using them you might be confused by the name of the label as it’s intent. Don’t fall into that trap, I did, and then I found this post on Google Groups… Check it out to gain more insight on how the configuration works and can be tweaked for your needs. There is also the standard documentation, but it’s a little light IMO.
Running Edda
Congrats you made it, time to run Edda ! Again the documentation has this wrong (listed as gradle & Jetty)…instead were using SBT + Jetty…
$ cd /cmdb/edda/ $ ./project/sbt > jetty:start
If everything goes smoothly you will start to see logs about crawling AWS API’s spewing to your screen 🙂 After about 2 minutes you should see data. You can check by doing a curl.
curl http://127.0.0.1:8080/api/v2/view/instances
This API URL should return a JSON object with instance ID’s for the account & region specified.
Additionally, Edda is listening on whatever private IP address you have setup, you will just need to modify the default security group to allow 8080 on your machine.
I get a bit frustrated with out of date documentation..so I hope this helps ! Happy automating !