
Spinnaker is a tool created by Netflix (of whom I have always been a big fan) that succeeded Asgard a tool I used in my past at PayPal. Not to digress but my favorite companies when it comes to DevOps tools are Hashicorp and Netflix. Obviously, that’s a bit of apples and oranges there, but they both make solid DevOps tools…Moving on…
Here is a quick overview on Spinnaker’s GUI
If you are familiar with Jenkins, then Spinnaker will make a lot of sense to you. Spinnaker is all about configuring a pipeline with stages to automate/orchestrate a number of steps with regards to ‘continously’ deploying your application code to an environment. Spinnaker puts the CD in CI/CD 😉 Corny, but had to say it…
Moving on…
To use Spinnaker effectively, you need to use Jenkins with it. Jenkins is responsible for your git / bake phase, where code is downloaded and then launched on a VM in your environment i.e. AWS. At the end of that launch assuming everything works out, a snapshot is taken and an AMI is created to be use in subsequent steps for install. A typical pipeline looks like this..
- Grab the latest checkin from Git repo
- Build a package rpm/deb of your application/code (+ dependencies)
- Install the package above, aka Bake the code on a VM in AWS, then take a snapshot ( create AMI)
- Subsequently deploy your code to compute / includes LB setup if there is any.
- Should also mention Spinnaker automatically sets up ASG (auto-scaling groups) which is a nice feature ( if a machine dies its re-created based on the capacity you set/require)
- And finally if you need a cleanup task such as “destroy the boxes running the old code” that runs.
Visually pipeline configuration, it looks like this…

Notice the shrink cluster step. This is one of Spinnaker’s built in stages that you can use. However, there is a better way to handle this vs. manually creating the ‘cleanup’ phases after a deploy. You can instead employ what are called strategies…
For example, if you click Deploy in the pipeline to go to the configuration for that…. and then click on edit under a Server Group you have created under Deploy Configuration…

You will get a new window popup that looks like this… .

As you can see here I have clicked into Strategy, and am currently using Highlander which states ‘Destroys all previous server groups in the cluster as soon as new server group passes health checks’.
The highlander strategy is extremely useful for rolling out new builds. Essentially your old code will run, until your new code is healthy at which point the old server groups is destroyed. Assuming the new build is healthy (i.e. your health checks and all previous build tests etc have good coverage) you should be good to go to the shortest amount of time possible. I tried all sorts of customizations to my pipeline to emulate the above behavior without using the strategy and found that the highlander strategy is the fastest.
Anyway, your use cases may be different depending on the type of pipeline you are configuring. So take some time to familiarize yourself with the availability strategies depending on your specific use case.
Now I kinda jumped ahead a few chapters, but I did that to make the point quick before you lose interest, that Spinnaker will deploy your code, it will make sure your nodes are always running, and it can do this all automatically once configured…
What I mean is if we go backwards now to the original configuration step let’s look at your Configuration step in the pipeline…
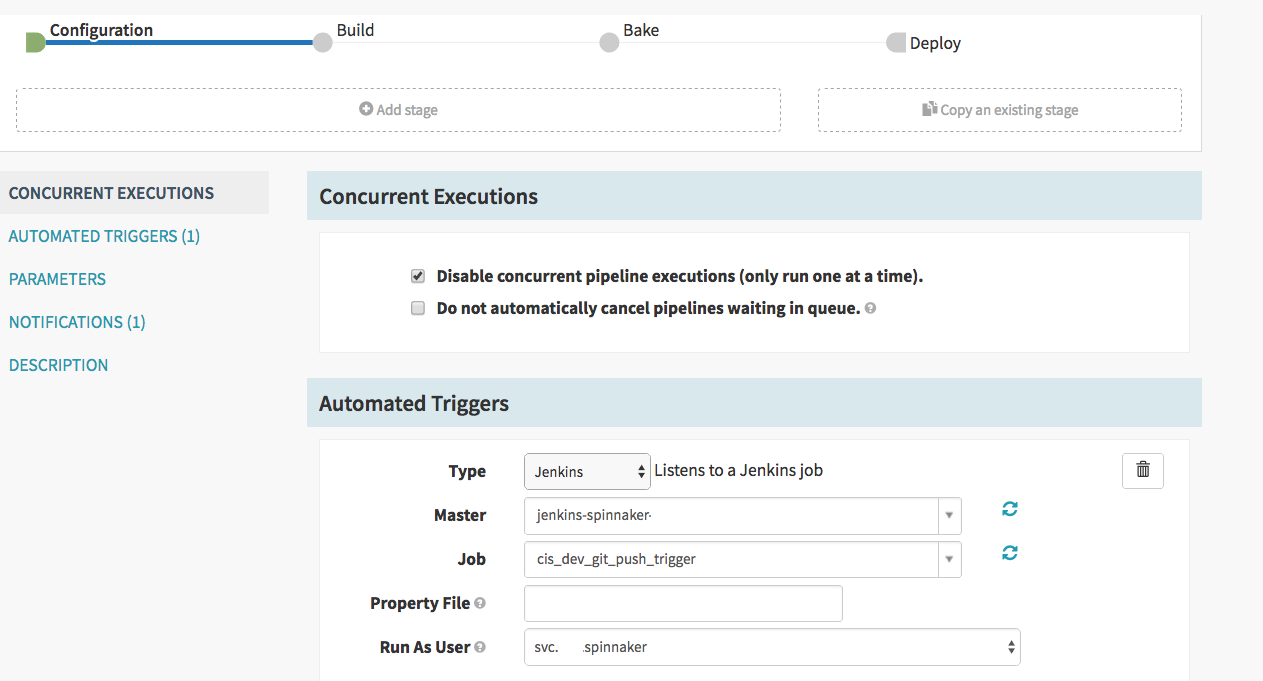
Under the section called “Automated Triggers” I have added some configuration to listen to a Jenkins server for changes on a Job that I have defined in Jenkins. I am not going to go into much detail on Jenkins because this article would be too longer, but just to show this job in Jenkins very quickly for a full understanding.
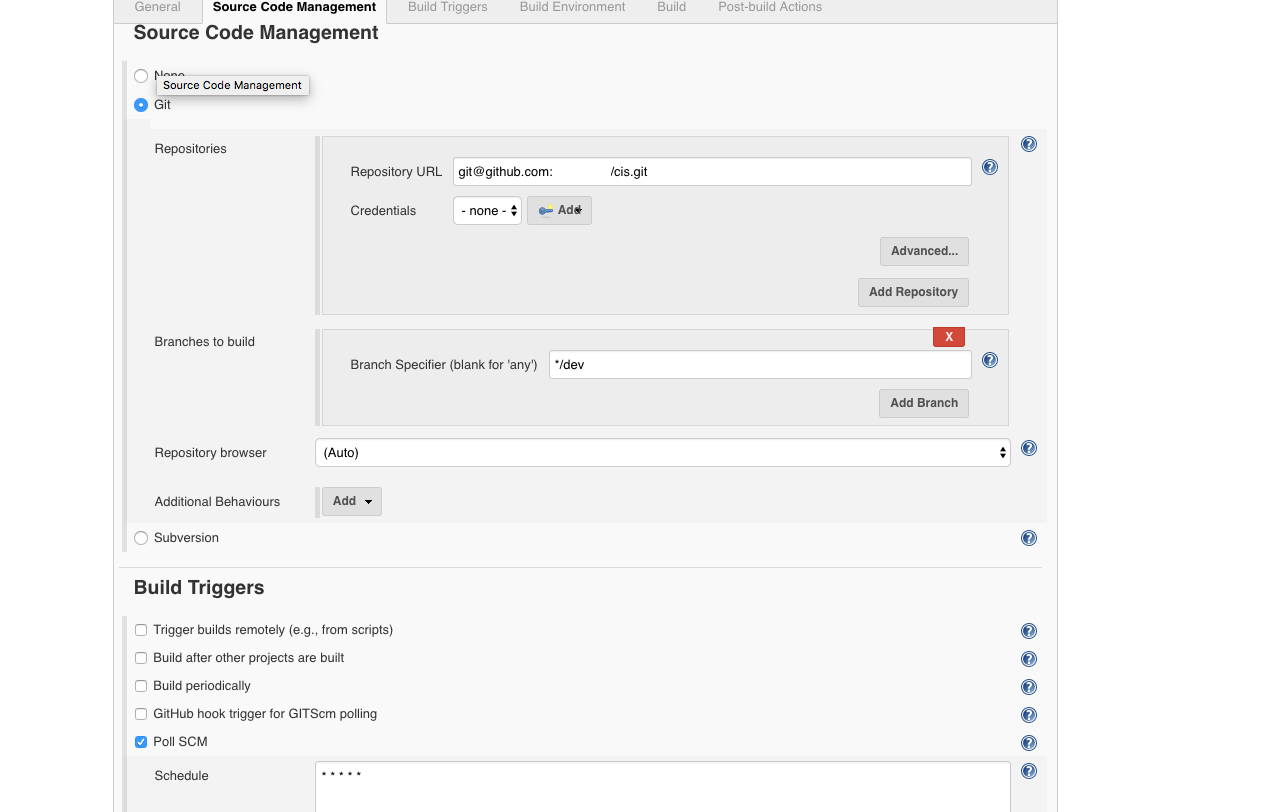
This is a screenshot of a job that polls Git every minute for changes. So with these configured, Spinnaker will Listen for changes to our specified repo via Jenkins. Subsequently, if changes are detected Spinnaker will proceed with the rest of the pipeline configuration. The next step is Build.
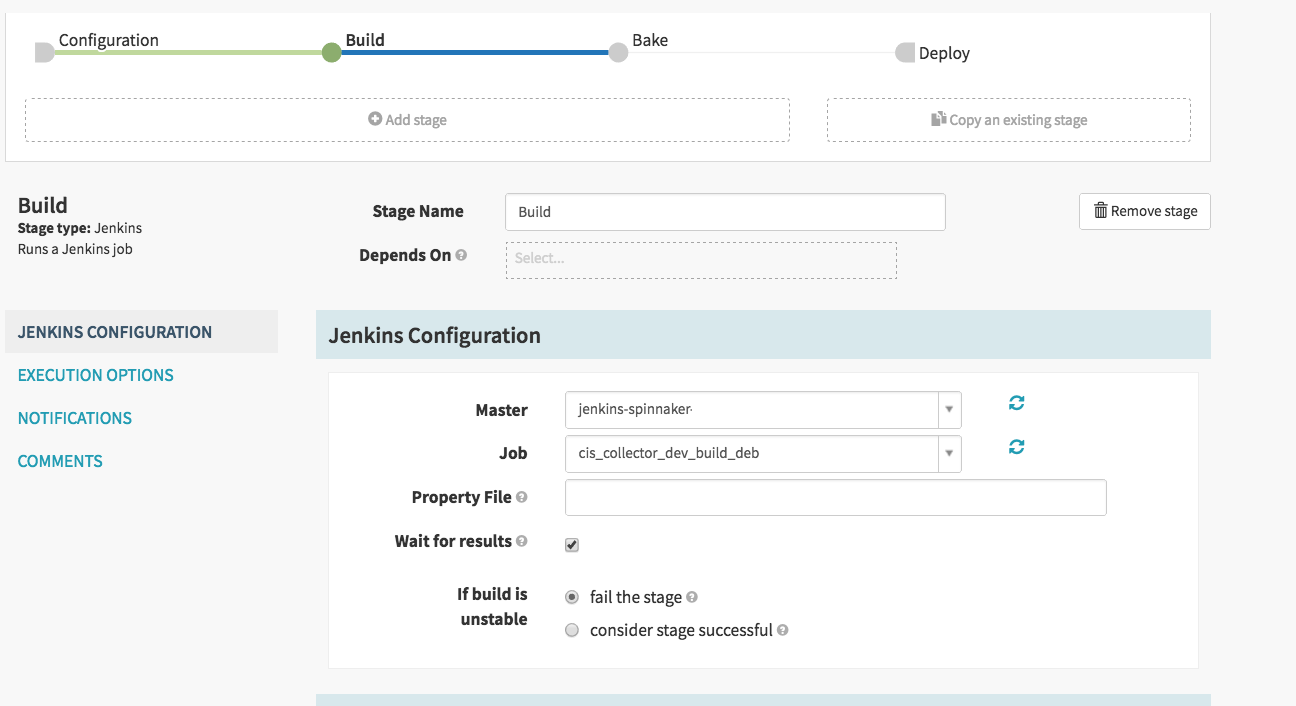
The first step ‘Configuration’ detects changes to our git repo. The second step Build, turns those changes into an installable package again utilizing Jenkins to do this. Here we tell spinnaker to run our build job in Jenkins…let’s take a look at that in Jenkins…first we do our git configuration, and nothing under build triggers.
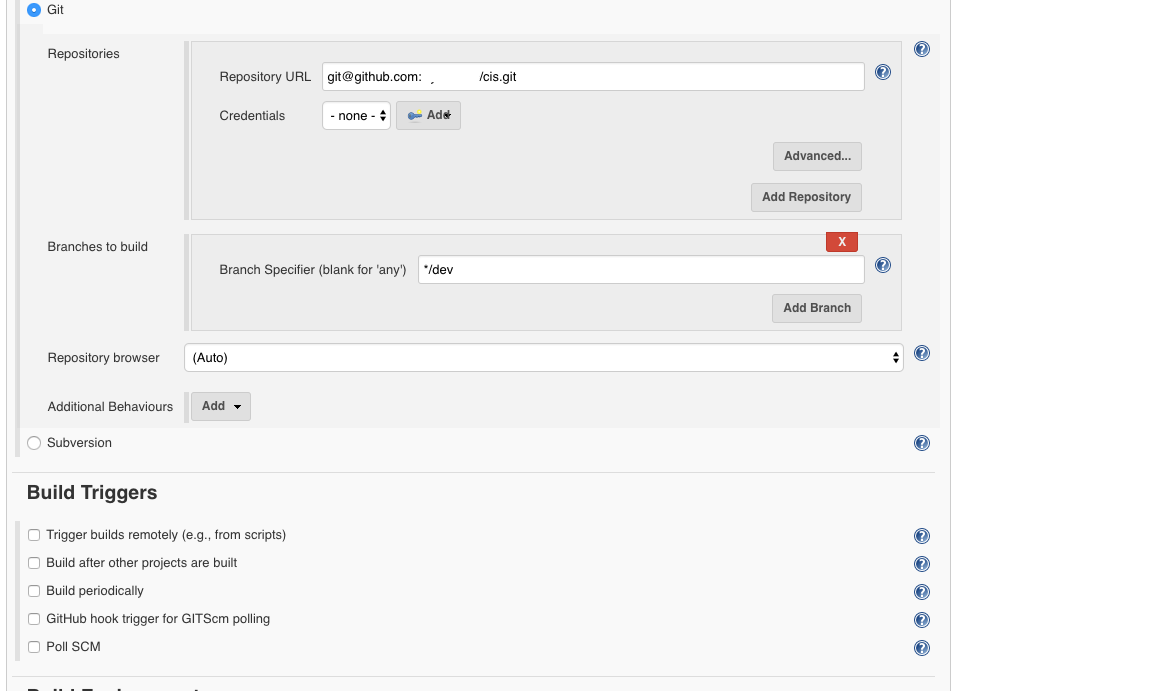
Then if necessary we can inject files during build time for packaging..
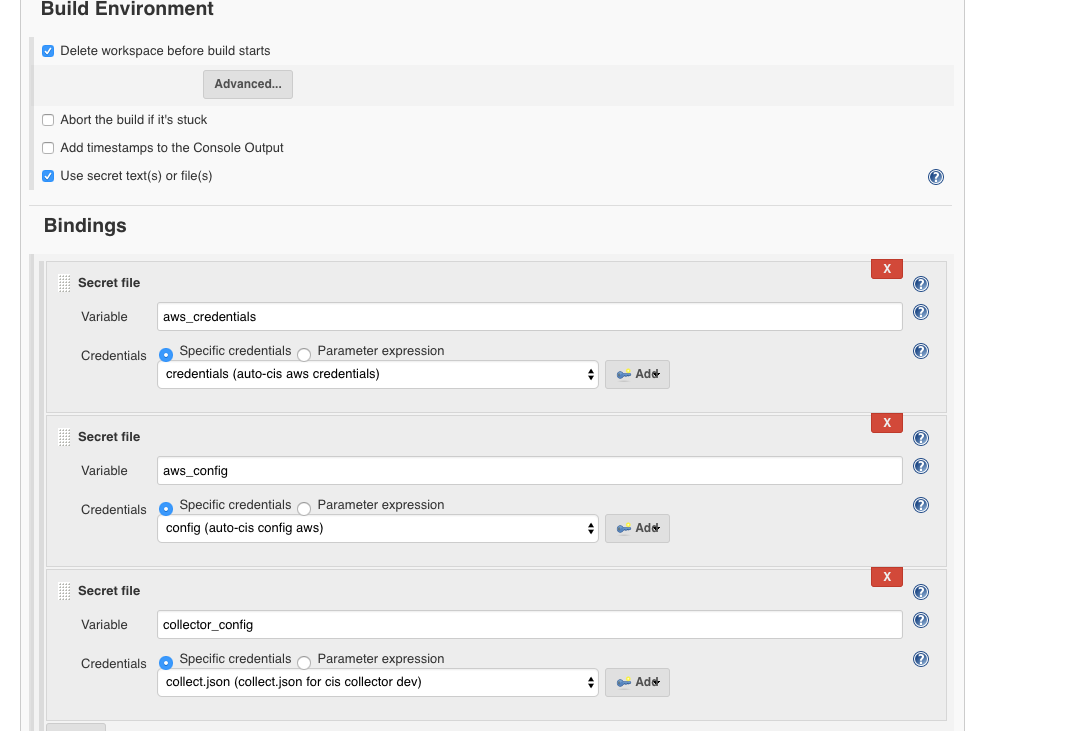
To make use of the injected files we must copy them from a variable to the host using a build step to execute a shell…
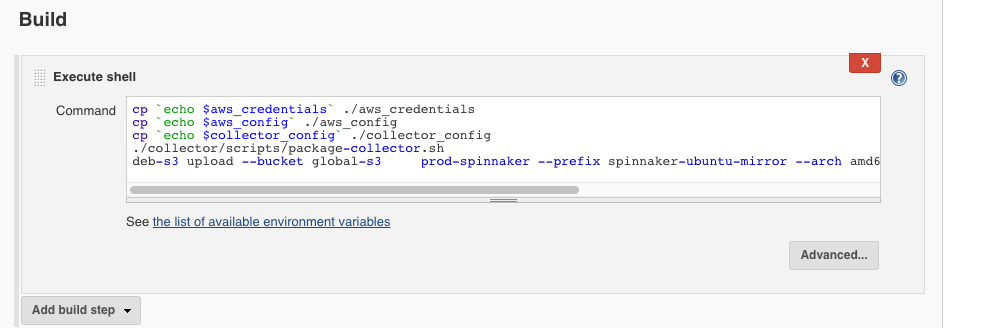
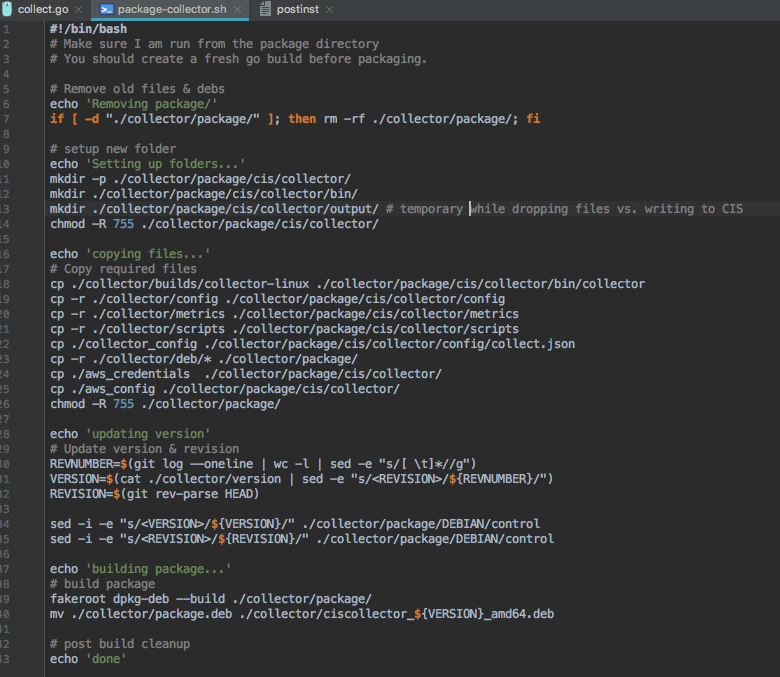
We then run our actual packaging script that turns it into an rpm/deb etc. Mine is called ‘package-collector.sh’ and looks like this…
And finally there is magic… The last line of our executed shell build step uploads our package to S3….
deb-s3 upload --bucket global-s3-prod-spinnaker --prefix spinnaker-ubuntu-mirror --arch amd64 --codename trusty --preserve-versions true ./collector/*.deb
And the last step in our Jenkins is to archive the artifacts.
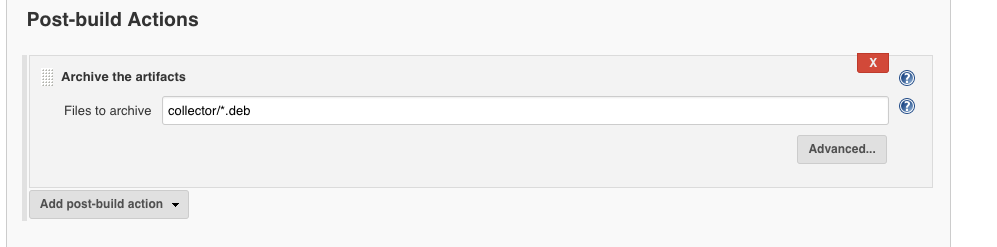
The end of the output of this Job when run looks like this.
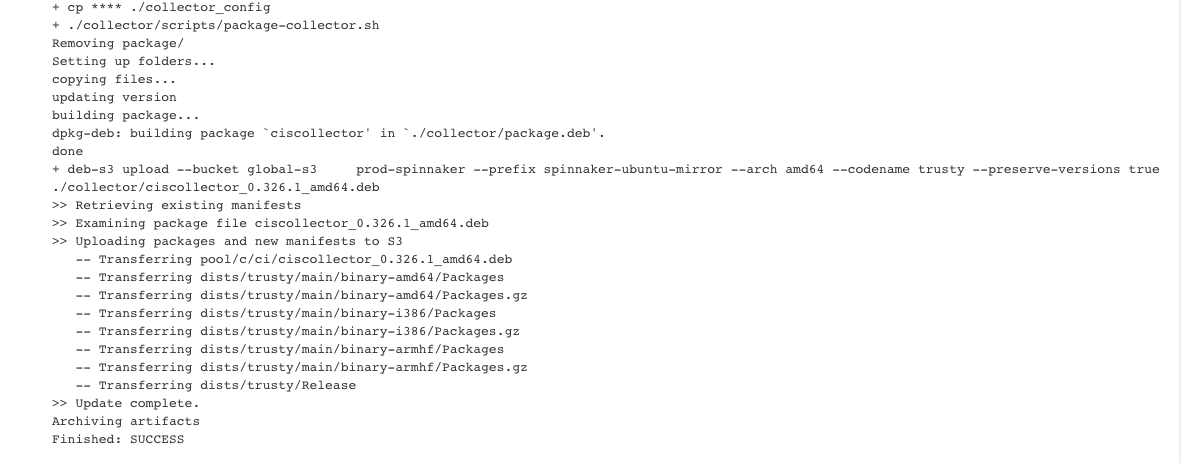
Next Spinnaker goes to Bake, this is the step where the package gets installed to a VM “baked” and then snapshotted and turned to an AMI for the Deploy step.
The Bake step in Spinnaker is the most straight forward…
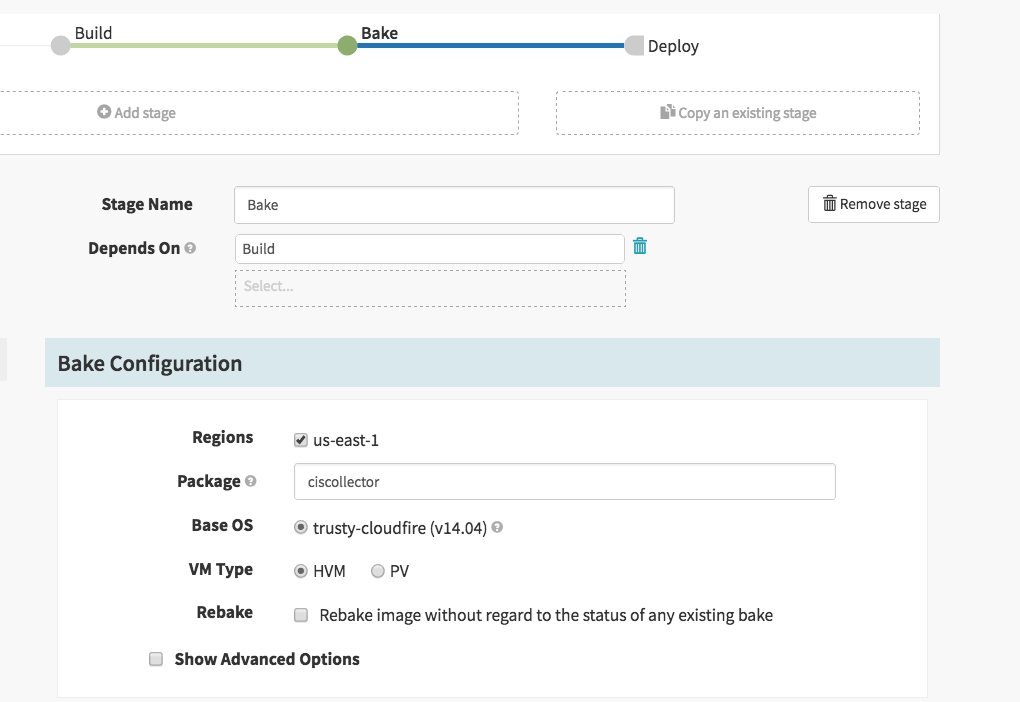
Essentially, as long as your package name ‘ciscollector’ as shown here matches the base name of the package you are creating, Spinnaker (is already configured to look in our S3 bucket) will find it and install it on a VM, at the end it will snapshot that VM and created an AMI to use to install in the subsequent Deploy stage of the pipeline.
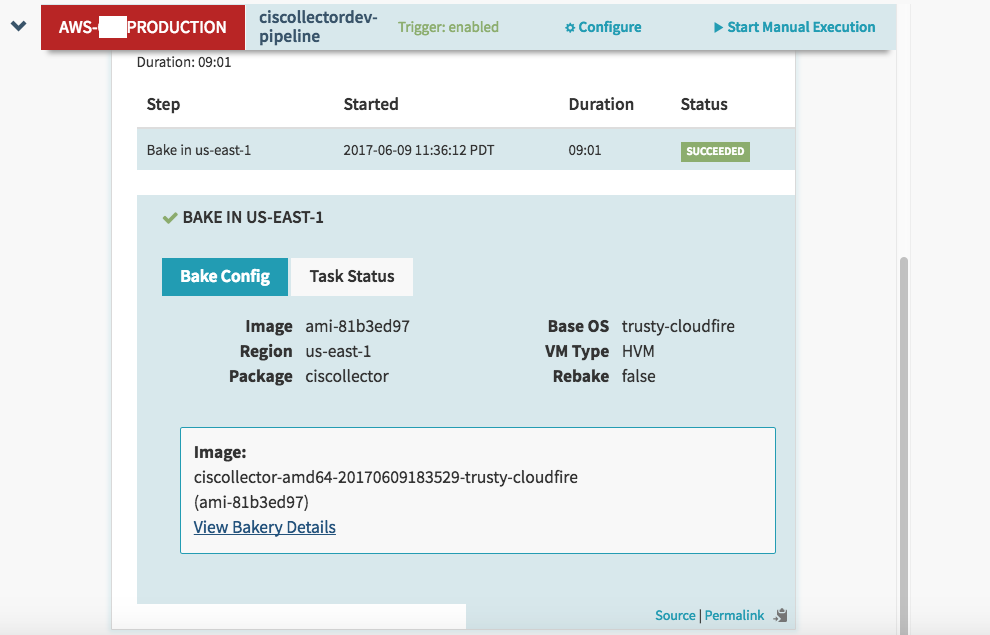
Finally, we are back to the Deploy step. The deploy step depends on the bake step, just like the bake step depends on build and build depends on Configuration. This is how we create the workflow of our pipeline using ‘depends on’ ( sorry for not explaining that sooner ). So when Build completes successfully we start our Deploy step, which as shown before, has a server group created. Of course you will not, so you must create a new server group, which is how Spinnaker manages/groups servers & load balancers for deployments.
The deploy steps requires that you fill out the following sections with your specific configuration…

As discussed previously under Basic Settings it is best to pick a strategy as part of the Deploy stage rather then trying to do many custom/complicated things yourself. So rather then screenshot through this… it’s pretty self-explanatory to configured Load Balancers, Security Groups, Instance Type etc… The one thing I would highlight is the capacity section and also tagging under Advanced Settings.
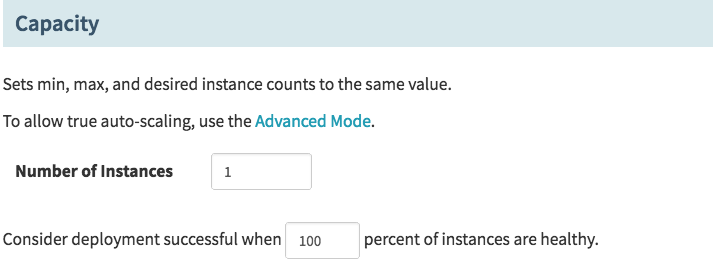
The capacity section is important for 2 reasons. First whatever you set for number of instances, turns into an auto-scaling group requirement, thus whatever you set there, if a node is killed or lost for any reason, your auto-scaling group in AWS will make sure you always have that number of nodes running. This is helpful if nodes are dying for whatever reason, although not super helpful if they continually die quickly due to misconfiguration, etc. The second part about consider deployments successful when % of instances are healthy is very important for the speed of your pipeline. Let’s say you have a pool of 16 servers… if all those servers run the same image, the chances that you need to wait until 100% here are slim, for example lets say you run 4 servers, and you only need 3 servers to service 100% of capacity for request. In this case it would be acceptable to move on from this Deploy step at 75% capacity, because waiting for the last 25% isn’t really necessary to service request and you are 99% sure that last host is going to come up. So feel free to tweak.
Last as mentioned, make sure you take the opportunity to tag things in the Advanced Settings sections.
Another highlight, is this is where you would inject userdata to Ec2 instances (under advanced settings). This is helpful when you want to past at-boot-time configuration to a system. For example, you might want to override a configuration file at boot time and say something like if I get this value in user data, override the config, if I don’t use the config. Just remember to pass your userdata as base64.
I want to leave you with some final comments. Spinnaker is a great deployment tool. It is helpful to use the pipeline/stage workflow for reproducing deployments, however, there are many limitations that Spinnaker has, and it will always lag on feature set parity with providers like AWS. As an example, the ALB support is quite limited at the time of this writing. So for that I had to add a custom Jenkins step that runs a script on the Jenkins server to manually add nodes to target groups for an ALB. If you are interested or need more details on that solution email me at tuxninja@tuxlabs.com
I hope you found this brief overview on Spinnaker useful. It’s a great tool that can be used to easily reproduce application deployments.