
In the video below I walk through how to parse JSON data from a REST API using Python and the Requests library and json standard library for Python. I also drop a little nugget on duck typing. Hope you enjoy!
Programming
There are 14 posts filed in Programming (this is page 1 of 3).
How To: Create An AWS Lambda Function To Backup/Snapshot Your EBS Volumes
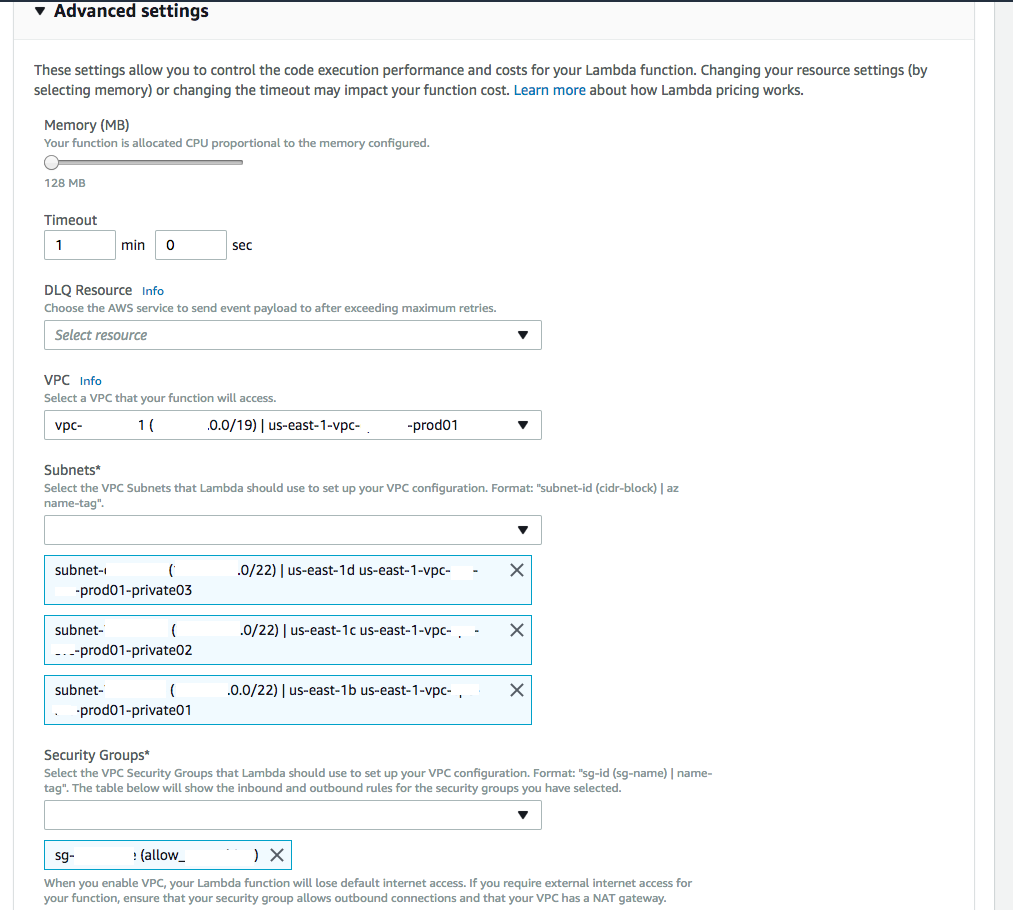
AWS Lambda functions are a great way to run some code on a trigger/schedule without needing a whole server dedicated to it. They can be cost effective, but be careful depending on how long they run, and the number of executions per hour, they can be quite costly as well.
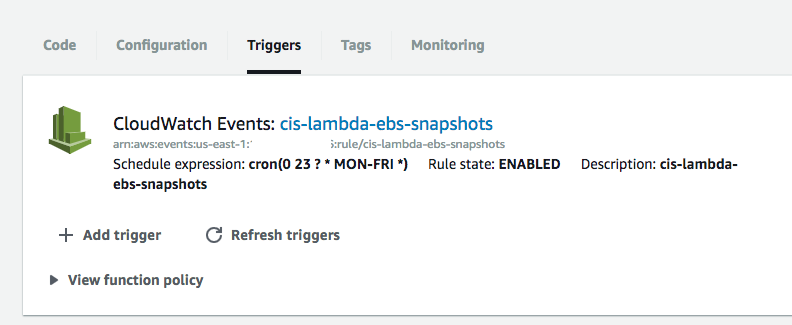
For my use case, I wanted to create snapshot backups of EBS volumes for a Mongo Database every day. I originally implemented this using only CloudWatch, which is a monitoring service, but because it’s focused on scheduling, AWS also uses it for other things that require scheduling/cron like features. Unfortunately, the CloudWatch implementation of snapshot backups was very limited. I could not ‘tag’ the backups, which was certainly something I needed for easy finding and cleanups later (past a retention period).
Anyway, there were a couple pitfalls I ran into when creating this function.
Pitfalls
- Make sure you security group allows you to communicate to the Internet for any AWS API’s you need to talk to.
- Make sure your time-out is set to 1 minute or greater depending on your use case. The default is seconds, and is likely not high enough.
- “The Lambda function execution role must have permissions to create, describe and delete ENIs. AWS Lambda provides a permissions policy,
AWSLambdaVPCAccessExecutionRole, with permissions for the necessary EC2 actions (ec2:CreateNetworkInterface,ec2:DescribeNetworkInterfaces, andec2:DeleteNetworkInterface) that you can use when creating a role”- Personally, I did inline permissions and included the specific actions.
- Upload your zip file and make sure your handler section is configured with the exact file_name.method_in_your_code_for_the_handler
- Also this one is more of an FYI, Lambda Function have a maximum TTL of 5 minutes ( 300 seconds).
I think that was it, after that everything worked fine. To finish this short article off, screenshots and the code!
Screenshots

And finally the code…
Function Code
# Backup cis volumes
import boto3
def lambda_handler(event, context):
ec2 = boto3.client('ec2')
reg = 'us-east-1'
# Connect to region
ec2 = boto3.client('ec2', region_name=reg)
response = ec2.describe_instances(Filters=[{'Name': 'instance-state-name', 'Values': ['running']},
{'Name': 'tag-key', 'Values': ['Name']},
{'Name': 'tag-value', 'Values': ['cis-mongo*']},
])
for r in response['Reservations']:
for i in r['Instances']:
for mapping in i['BlockDeviceMappings']:
volId = mapping['Ebs']['VolumeId']
# Create snapshot
result = ec2.create_snapshot(VolumeId=volId,
Description='Created by Lambda backup function ebs-snapshots')
# Get snapshot resource
ec2resource = boto3.resource('ec2', region_name=reg)
snapshot = ec2resource.Snapshot(result['SnapshotId'])
# Add volume name to snapshot for easier identification
snapshot.create_tags(Tags=[{'Key': 'Name', 'Value': 'cis-mongo-snapshot-backup'}])
And here is an additional function to add for cleanup
import boto3
from datetime import timedelta, datetime
def lambda_handler(event, context):
# if older than days delete
days = 14
filters = [{'Name': 'tag:Name', 'Values': ['cis-mongo-snapshot-backup']}]
ec2 = boto3.setup_default_session(region_name='us-east-1')
client = boto3.client('ec2')
snapshots = client.describe_snapshots(Filters=filters)
for snapshot in snapshots["Snapshots"]:
start_time = snapshot["StartTime"]
delete_time = datetime.now(start_time.tzinfo) - timedelta(days=days)
if start_time < delete_time:
print 'Deleting {id}'.format(id=snapshot["SnapshotId"])
client.delete_snapshot(SnapshotId=snapshot["SnapshotId"], DryRun=False)
The end, happy server-lessing (ha !)
How To: Interact with AWS S3 Using the Go SDK and not lose your mind

After these messages we will carry on with our regularly scheduled programming…
Yesterday ( during the scribbling of this article ) AWS suffered one of it’s worst outages in history in the us-east-1 region. A reminder to us all to be multi-region and more importantly multi-cloud. Please see my other articles on HA deployments using AWS and my perspective & caution on the path to centralization or singularity we appear to be on (though the outage may help people wake up).
Now back to your regularly scheduled program…
My team and I are building a CMDB for AWS, which provides us with everything happening in our AWS environment + OS level metadata + change history. There will be a separate article on the CMDB journey, but today I want to focus on a specific service in AWS called S3, which is their object store. S3 is a bit of a special snowflake when it comes to AWS services and because of that I ran into challenges structuring my code, because up until S3 (which was the last service I wrote code for) everything had been very similar, and easily modularized. We will get to more detail, but let’s start this article by covering how to use the Go SDK for AWS.
Dependencies
This article assumes you already program in Go and have Go installed on your machine. To get started you will need a couple additional items.
- Download and install the SDK here : https://github.com/aws/aws-sdk-go
- This is the documentation for the SDK, you will need it, bookmark it : http://docs.aws.amazon.com/sdk-for-go/api/
- It is extremely helpful when working with the API’s to have aws-shell installed : https://github.com/awslabs/aws-shell
- This enables you to interact with AWS API’s on the fly so you can understand the output of commands as you are searching for what you are trying to accomplish.
The Collector Structure
The collector is the component in my CMDB architecture that does all the work of collecting the metadata that we shove into our CMDB. The collector is heavily threaded using go routines for performance. The basic structure looks like this.
- Call a go routine for each service you want to collect
- //pass in all accounts, regions (from config-file) and pre-established awsSessions to each account you are collecting
- Inside of a services go routine, loop overs accounts & regions
- Launch a go routine for each account & region
- Inside of those go routines make your AWS API call(s), example DescribeInstances
- Store the response (I loop through mine and store it in a map using the resource-id as the key)
- Finally, kick off another go routine to write to our API and store the data.
- Launch a go routine for each account & region
Ok, so hopefully that seems straight forward as a basic structure…let’s get to why S3 through me for a loop.
S3 Challenges
It will be best if I show you what I tried first, basically I tried to marry my existing pattern to S3 and that certainly was a bad idea from the start. Here was the structure of the S3 part of the code.
- The S3 go routine gets called from main.go
- //all accounts, regions and AWS Sessions are past into the next go routine
- Inside of the S3 go routine, loop over accounts & regions
- Launch a go routine for each account & region
- Inside of those go routines List S3 Buckets
- For each S3 buckets returned
- Call additional API’s such as GetBucketTagging()
- For each S3 buckets returned
- Inside of those go routines List S3 Buckets
- Launch a go routine for each account & region
- Inside of the S3 go routine, loop over accounts & regions
Ok so what happened ? I got a lot of errors that’s what 🙂 Ones like this….
BucketRegionError: incorrect region, the bucket is not in 'us-west-2' region status code: 301, request id:
At first, I thought maybe my code wasn’t thread safe…but that didn’t make much sense given the other services had no issues like this.
So as I debugged my code, I began to realize the buckets list I was getting, wasn’t limited to the region I was passing in/ establishing a session for.
Naturally, I googled can I list buckets for a single region ?
https://github.com/aws/aws-sdk-java/issues/920 (even though this is the Java SDK it still applies)..
"spfink commented on Nov 16, 2016 It is not possible to list the buckets in a single region. Regardless of the endpoint or region that you set, when calling list buckets you will get buckets from all regions. In order to determine the region of a bucket you can use getBucketLocation(String bucketName). https://github.com/aws/aws-sdk-java/blob/master/aws-java-sdk-s3/src/main/java/com/amazonaws/services/s3/AmazonS3.java#L1026”
Ah ok, the BucketList being returned on an AWS Session established with a specific account and region, ignores the region. Because S3 Buckets are global to an account, thus all buckets under an account are returned in the ListBuckets() call. I knew S3 buckets were global per account, but failed to expect a matching behavior/output when a specific region is passed into the SDK/API.
Ok so how then can I distinguish where a bucket actually lives?
As spfink says above, I needed to run GetBucketLocation() per bucket. Thus my code structure started to look like this…
- For each account, region
- ListBuckets
- For each bucket returned in that account, region
- GetBucketLocation
- If a LocationConstraint (region) is returned, set the new region (otherwise if response is null, do nothing)
- Get tags for the bucket in account, region
- For each bucket returned in that account, region
- ListBuckets
With this code I was still getting errors about region, but why ?
Well I made the mistake of thinking a ‘null’ response from the API for LocationConstraint had no meaning (or meant query it from any region), wrong (null actually means us-east-1 see from my google below) thus the IF condition evaluated false and the existing region from the outer loop was used because GetBucketLocation() returned null and this resulted in many errors.
Here’s what the google turned up..
https://github.com/aws/aws-cli/issues/564
"kyleknap commented on Mar 16, 2015 @xurume For buckets located in US Standard, the location constraint will be null. For S3, here is the list of region names with their corresponding regions: http://docs.aws.amazon.com/general/latest/gr/rande.html#s3_region. Notice that the location constraint is none for US Standard. The CLI uses the values in the region column for the --region parameter. So for S3's US Standard, you need to use us-east-1 as the region.”
So let’s clarify my mistakes…
- The S3 ListBuckets call returns all buckets under an account globally.
- It does not abide by a region configured in an API Session
- Thus I/you should not loop over regions from a config file for the S3 service.
- Instead I/you need to find a buckets ‘real’ location using GetBucketLocation
- Then set the region for actions other than ListBuckets (which is global per account and ignores region passed).
- GetBucketLocation returning null, doesn’t mean the bucket is global or that you can interact with the bucket from endpoint you please…it actually means us-east-1 http://docs.aws.amazon.com/general/latest/gr/rande.html#s3_region
The Working Code
So in the end the working code for S3 looks like this…
- collector/main.go fires off a bunch of go routines per service we are collecting for.
- It passes in accounts, and regions from a config file.
- For the S3 service/file under the ‘services’ package the entry point is a function called StoreS3Resources.
Everything in the code should be self explanatory from that point on. You will note a function call to ‘writeToCis’… CIS is the name of our internal CMDB project/service. Again, I will later be blogging about the entire system in detail once we open source the code. Please keep in mind this code is MVP, it will be changed a lot (optimization, modularized, bug fixes, etc) before & after we open source it, but for now he is the quick and dirty, but hopefully functional code 🙂 Use at your own risk !
package services
import (
"github.com/aws/aws-sdk-go/service/s3"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/aws"
"sync"
"fmt"
"time"
"encoding/json"
"strings"
)
var wgS3BucketList sync.WaitGroup
var wgS3GetBucketDetails sync.WaitGroup
var accountRegionsMap = make(map[string]map[string][]string)
var accountToBuckets = make(map[string][]string)
var bucketToAccount = make(map[string]string)
var defaultRegion string = "us-east-1"
func writeS3ResourceToCis(resType string, resourceData map[string]interface{}, account string, region string){
b, err := json.Marshal(resourceData)
check(err)
err, status, url := writeToCisBulk(resType, region, b)
check(err)
fmt.Printf("%s - %s - %s - %s - Bytes: %d\n", status, url, account, region, cap(b))
}
func StoreS3Resources(awsSessions map[string]*session.Session, accounts []string, configuredRegions []string) {
s3Start := time.Now()
wgS3BucketList.Add(1)
go func () {
defer wgS3BucketList.Done()
for _, account := range accounts {
awsSession := awsSessions[account]
getS3AccountBucketList(awsSession, account)
}
}()
wgS3BucketList.Wait()
getS3BucketDetails(awsSessions, configuredRegions)
s3Elapsed := time.Since(s3Start)
fmt.Printf("S3 completed in: %s\n", s3Elapsed)
}
func getS3AccountBucketList(awsSession *session.Session, account string) {
svcS3 := s3.New(awsSession, &aws.Config{Region: aws.String(defaultRegion)})
//list returned is for all buckets in an account ( no regard for region )
resp, err := svcS3.ListBuckets(nil)
check(err)
var buckets []string
for _,bucket := range resp.Buckets {
buckets = append(buckets, *bucket.Name)
//reverse mapping needed for lookups in other funcs
bucketToAccount[*bucket.Name] = account
}
//a list of buckets per account
accountToBuckets[account] = buckets
}
func getS3BucketLocation(awsSession *session.Session, bucket string, bucketToRegion map[string]string, regionToBuckets map[string][]string) {
wgS3GetBucketDetails.Add(1)
go func() {
defer wgS3GetBucketDetails.Done()
svcS3 := s3.New(awsSession, &aws.Config{Region: aws.String(defaultRegion)}) // default
var requiredRegion string
locationParams := &s3.GetBucketLocationInput{
Bucket: aws.String(bucket),
}
respLocation, err := svcS3.GetBucketLocation(locationParams)
check(err)
//We must query the bucket based on the location constraint
if strings.Contains(respLocation.String(), "LocationConstraint") {
requiredRegion = *respLocation.LocationConstraint
} else {
//if getBucketLocation is null us-east-1 used
//http://docs.aws.amazon.com/general/latest/gr/rande.html#s3_region
requiredRegion = "us-east-1"
}
bucketToRegion[bucket] = requiredRegion
regionToBuckets[requiredRegion] = append(regionToBuckets[requiredRegion], bucket)
accountRegionsMap[bucketToAccount[bucket]] = regionToBuckets
}()
}
func getS3BucketsTags(awsSession *session.Session, buckets []string, account string, region string) {
wgS3GetBucketDetails.Add(1)
go func() {
defer wgS3GetBucketDetails.Done()
svcS3 := s3.New(awsSession, &aws.Config{Region: aws.String(region)})
var resourceData = make(map[string]interface{})
for _, bucket := range buckets {
taggingParams := &s3.GetBucketTaggingInput{
Bucket: aws.String(bucket),
}
respTags, err := svcS3.GetBucketTagging(taggingParams)
check(err)
resourceData[bucket] = respTags
}
writeS3ResourceToCis("buckets", resourceData, account, region)
}()
}
func getS3BucketDetails(awsSessions map[string]*session.Session, configuredRegions []string) {
for account, buckets := range accountToBuckets {
//reset regions for each account
var bucketToRegion = make(map[string]string)
var regionToBuckets = make(map[string][]string)
for _,bucket := range buckets {
awsSession := awsSessions[account]
getS3BucketLocation(awsSession, bucket, bucketToRegion, regionToBuckets)
}
}
wgS3GetBucketDetails.Wait()
//Preparing configured regions to make sure we only write to CIS for regions configured
var configuredRegionsMap = make(map[string]bool)
for _,region := range configuredRegions {
configuredRegionsMap[region] = true
}
for account := range accountRegionsMap {
awsSession := awsSessions[account]
for region, buckets := range accountRegionsMap[account] {
//Only proceed if it's a configuredRegion from the config file.
if _, ok := configuredRegionsMap[region]; ok {
fmt.Printf("%s %s has %d buckets\n", account, region, len(buckets))
getS3BucketsTags(awsSession, buckets, account, region)
} else {
fmt.Printf("Skipping buckets in %s because is not a configured region\n", region)
}
}
}
wgS3GetBucketDetails.Wait()
}
How To: Launch EC2 Instances In AWS Using The AWS CLI
![]()
It occurred to me recently that while I have written articles on Boto for AWS (the Python SDK) I have yet to write articles on how to use the AWS CLI, Terraform and the Go SDK. All of that will come in due time, for starters this article is going to be about the AWS CLI.
To start you will need to install the AWS CLI following these links:
https://aws.amazon.com/cli/
https://github.com/aws/aws-cli
Note you will need to make sure you have an account with an access key and have setup the required credentials under ~/.aws/ for the CLI to work. How to do this is covered near the end of the second link above to the git repo.
After that is done you are ready to rock and roll. To test it out you can run…
aws ec2 describe-instances
Assuming your default region, and profile settings are correct it should output JSON.
Launching an EC2 instance
To launch an EC2 instance from the command line use the command below replacing the variables preceded with $ with their real values.
aws --profile $account --region $region ec2 run-instances --image-id $image_id --count $count --instance-type $instance_type --key-name $ssh_key_name --subnet-id $subnet_id
(Assuming you have setup the required dependencies like uploading your SSH key to AWS and specifying its name in the command above this should launch your VM).
It should be noted there is a lot more you can to to tweak your instance, such as changing the EBS volume size for your root disk that is launched or tagging. You will see examples of this in my shell script. The purpose of this article is to share a shell script I have written and use whenever I want to quickly launch a test VM (which is common). For more permanent things I use an infrastructure as code approach via Terraform. But the need for launching quick test VM’s never goes away, thus this shell script was born. You will notice my script auto-tags our VM’s…I do this because in our environment if you VM isn’t tagged appropriately it is deleted + it’s courtesy in an AWS environment to tag your resources, otherwise no one will ever what tree to bark up when there is a problem such as ‘are you still using this cause it looks idle?’ 🙂
My Shell Script for Launching EC2 VM’s
#!/bin/bash
# Global Settings
account="my-account"
region="us-east-1"
# Instance settings
image_id="ami-03ebd214" # ubuntu 14.04
ssh_key_name="my_ssh_key-rsa-2048"
instance_type="m4.xlarge"
subnet_id="subnet-b8214792"
root_vol_size=20
count=1
# Tags
tags_Name="my-test-instance"
tags_Owner="tuxninja"
tags_ApplicationRole="Testing"
tags_Cluster="Test Cluster"
tags_Environment="dev"
tags_OwnerEmail="tuxninja@tuxlabs.com"
tags_Project="Test"
tags_BusinessUnit="Cloud Platform Engineering"
tags_SupportEmail="tuxninja@tuxlabs.com"
echo 'creating instance...'
id=$(aws --profile $account --region $region ec2 run-instances --image-id $image_id --count $count --instance-type $instance_type --key-name $ssh_key_name --subnet-id $subnet_id --block-device-mapping "[ { \"DeviceName\": \"/dev/sda1\", \"Ebs\": { \"VolumeSize\": $root_vol_size } } ]" --query 'Instances[*].InstanceId' --output text)
echo "$id created"
# tag it
echo "tagging $id..."
aws --profile $account --region $region ec2 create-tags --resources $id --tags Key=Name,Value="$tags_Name" Key=Owner,Value="$tags_Owner" Key=ApplicationRole,Value="$tags_ApplicationRole" Key=Cluster,Value="$tags_Cluster" Key=Environment,Value="$tags_Environment" Key=OwnerEmail,Value="$tags_OwnerEmail" Key=Project,Value="$tags_Project" Key=BusinessUnit,Value="$tags_BusinessUnit" Key=SupportEmail,Value="$tags_SupportEmail" Key=OwnerGroups,Value="$tags_OwnerGroups"
echo "storing instance details..."
# store the data
aws --profile $account --region $region ec2 describe-instances --instance-ids $id > instance-details.json
echo "create termination script"
echo "#!/bin/bash" > terminate-instance.sh
echo "aws --profile $account --region $region ec2 terminate-instances --instance-ids $id" >> terminate-instance.sh
chmod +x terminate-instance.sh
After substituting the required variables at the top with your real values you can run this script. Notice that after creating the VM I capture the instance details in a file & the ID in a variable so I can subsequently tag it, and then I create a termination script…this makes for very simple operations when you need to repeatedly start and then kill/destroy/delete a VM.
Using these scripts should come in quite handy. A copy of create-instance.sh can be found on my github here.
One other thing… I use the normal AWS CLI for automation as shown here…but for poking around interactively I use something called ‘aws-shell’ formerly ‘saw’. Check it out and you won’t be disappointed !
My next post will be on Terraform or the Go SDK…but both are coming soon!
A simple, concurrent webcrawler written in Go
I have been playing with the Go programming language on an off for about a year. I started learning Go, because I was running into lots of issues distributing my Python codes dependencies to production machines, with specific security constraints. Go solves this problem by allowing you to compile a single binary that can be easily copied to all of your systems and you can cross compile it easily for different platforms. In addition, Go has a really great & simple way of dealing with concurrency, not to mention it really is concurrent unlike my beloved Python (GIL), which is great for plenty of use cases, but sometimes you need real concurrency. Here is some code I wrote for a simple concurrent webcrawler.
Here is the code for the command line utility fetcher. Notice it imports another package, crawler.
package main
import (
"flag"
"fmt"
"strings"
"github.com/jasonriedel/fetcher/crawler"
"time"
)
var (
sites = flag.String("url", "", "Name of sites to crawl comma delimitted")
)
func main() {
flag.Parse()
start := time.Now()
count := 0
if *sites != "" {
ch := make(chan string)
if strings.Contains(*sites, ",") {
u := strings.Split(*sites, ",")
for _, cu := range u {
count++
go crawler.Crawl(cu, ch) // start goroutine
}
for range u {
fmt.Println(<-ch)
}
} else {
count++
go crawler.Crawl(*sites, ch) // start goroutine
fmt.Println(<-ch)
}
} else {
fmt.Println("Please specify urls")
}
secs := time.Since(start).Seconds()
fmt.Printf("Total time: %.2fs - %d site(s)", secs, count)
}
I am not going go over the basics in this code, because that should be fairly self explanatory. What is important here is how we are implementing concurrency. Once the scripts validates you passed a string in (that is hopefully a URL – No input validation yet!) it starts by creating a channel via
ch := make(chan string)
After we initialized the channel, we need to split the sites passed in from the command line -url flag via comma in case there is more than 1 site to crawl. Then we loop through each site and kick off a go routine like so.
go crawler.Crawl(cu, ch) // start goroutine
At this point, our go routine is executing code from the imported crawler package mentioned above. Calling the method Crawl. Let’s take a look at it now…
package crawler
import (
"fmt"
"time"
"io/ioutil"
"io"
"net/http"
)
func Crawl(url string, ch chan<- string) {
start := time.Now()
resp, err := http.Get(url)
if err != nil {
ch <- fmt.Sprint(err) // send to channel ch
return
}
nbytes, err := io.Copy(ioutil.Discard, resp.Body)
resp.Body.Close() // dont leak resources
if err != nil {
ch <- fmt.Sprintf("While reading %s: %v", url, err)
return
}
secs := time.Since(start).Seconds()
ch <- fmt.Sprintf("%.2fs %7d %s", secs, nbytes, url)
}
This is pretty straight forward. We start a timer, take the passed in URL and do an http.get …if that doesn’t error, the response Body is copied into nbytes, which is ultimately returned to the channel at the bottom of the function.
Once the code returns from crawler.Crawl to fetcher… it loops through each URL for channel output. This is very important. If you try placing a print inside of the same loop as your go routine you are going to change the behavior of your application to work in a serial/slower fashion because after each go routine it will wait for output. Putting the loop for channel output outside of the loop that launches the go routine enables them to all be launched one right after another, and then output is gathered after they have all been launched. This creates a very highly performant outcome. Here is an example of this script once it has been compiled.
➜ fetcher ./fetcher -url http://www.google.com,http://www.tuxlabs.com,http://www.imdb.com,http://www.southwest.com,http://www.udemy.com,http://www.microsoft.com,http://www.github.com,http://www.yahoo.com,http://www.linkedin.com,http://www.facebook.com,http://www.twitter.com,http://www.apple.com,http://www.betterment.com,http://www.cox.net,http://www.centurylink.net,http://www.att.com,http://www.toyota.com,http://www.netflix.com,http://www.etrade.com,http://www.thestreet.com 0.10s 195819 http://www.toyota.com 0.10s 33200 http://www.apple.com 0.14s 10383 http://www.google.com 0.37s 57338 http://www.facebook.com 0.39s 84816 http://www.microsoft.com 0.47s 207124 http://www.att.com 0.53s 294608 http://www.thestreet.com 0.65s 264782 http://www.twitter.com 0.66s 428256 http://www.southwest.com 0.74s 99983 http://www.betterment.com 0.80s 41372 http://www.linkedin.com 0.82s 520502 http://www.yahoo.com 0.87s 150688 http://www.etrade.com 0.89s 51826 http://www.udemy.com 1.13s 71862 http://www.tuxlabs.com 1.16s 25509 http://www.github.com 1.30s 311818 http://www.centurylink.net 1.33s 169775 http://www.imdb.com 1.33s 87346 http://www.cox.net 1.75s 247502 http://www.netflix.com Total time: 1.75s - 20 site(s)%
20 sites in 1.75s seconds..that is not too shabby. The remainder of the fetcher code runs a go routine if only one site is passed..then returns an error if message if a url is not passed in on the command line, and finally outputs the time it took total to run for all sites. The go routine is not necessary in the case of running a single url, however, it doesn’t hurt and I like the consistency of how the code reads this way.
Hopefully you enjoyed this brief show of the Go programming language. If you decide to get into Go, I cannot recommend this book enough : https://www.amazon.com/Programming-Language-Addison-Wesley-Professional-Computing/dp/0134190440 . This book has a bit of a cult following due to one of the authors being https://en.wikipedia.org/wiki/Brian_Kernighan who co-authored what consider to be the best book on C ever written (I own it, it’s really good too). I bought other Go books before this one, and I have to say don’t waste your money, buy this one and it is all you will need.
The github code for the examples above can be found here : https://github.com/jasonriedel/fetcher
Godspeed, happy learning.